Israel’s machine learning infrastructure: Part Deux
One year ago we published our outline of the Israeli startups in the machine learning infrastructure space. That article detailed what was still considered a burgeoning sub-sector of the overall machine learning industry, one of the defining technological trends of our generation. The simple thesis being that along with a new class of software comes new infrastructure to support it.
A year later, this sub-sector has evolved into a sector in its own right. In Israel alone, there were an additional 22 startups founded in this sector in the past 12 months!
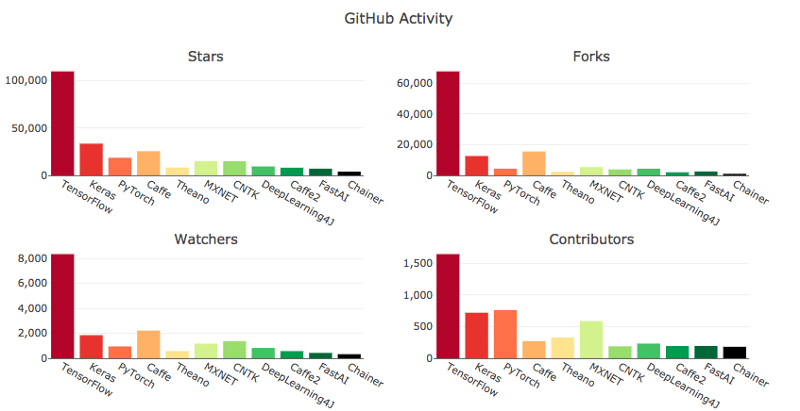
As machine learning continues to proliferate in both the consumer and enterprise realms, the need for specialised tools has become quite apparent. As discussed in part one, the major cloud providers each have a horse in this race. And as can be seen in the image below, Google, with TensorFlow, is currently leading the pack.
But the cloud providers’ foray into the machine learning infrastructure world has taken many steps beyond the “simple” deep learning frameworks mentioned above. Kubernetes (also a Google asset) now serves as a critical building block for most new tools in the space (for example: Kubeflow, Pachyderm, Seldon).
The above evidence leads to the question we ask fledgling startups in the ML infrastructure space most often: is there a true startup opportunity here? And furthermore, is there a true opportunity for an Israeli startup to succeed?
On a macro level we believe the answer to this question to be a resounding yes, and the below landscape seems to indicate that entrepreneurs feel the same way. On a micro level however, it is necessary to dig deeper into the challenges that scaling a machine learning practice presents in order to truly understand where the opportunities lay.

Show Me The Data!
We live in a world where data is aplenty. The sheer amount of edge devices that are constantly capturing and streaming data to data centers around the world is staggering. Despite this, one of the most significant bottlenecks for running machine learning end-to-end is spent on data preparation, which is a term that includes several steps such as collecting, cleaning, understanding, and feature engineering. Interestingly enough, data collection has proven to be one of the most difficult aspects within the larger challenge of data preparation. To be clear, the problem is not that the data doesn’t exist, rather that acquiring the necessary datasets for a specific use case can be incredibly time consuming and frustrating.
We have seen three main approaches to deal with this challenge:
- Data discovery and augmentation — as more datasets are available online and in corporate data lakes, it is possible to find data that meets the needs of specific use cases. Explorium.ai is a great example of this and has a solution that comes to solve precisely this issue.
- Data annotation— simply acquiring datasets is not enough. Once collected, the data must be labeled in order for it to be used effectively in models.
- Data Generation — An alternative to sourcing existing datasets is to generate synthetic datasets instead. One of the challenges in creating synthetic data is that the dataset must be realistic enough to train a model effectively, which is no trivial task. Datagen (a TLV Partners portfolio company) is pioneering the synthetic data creation space by offering a platform for the automatic generation of photorealistic 3D images for human and human interaction datasets. A main benefit of Datagen’s platform and other synthetic data providers, is that this type of data comes pre-annotated. Due to the lengthy and costly process of annotating data we expect to see a significant rise in the adoption of synthetic data.
While we expect to continue to see innovation in the data preparation field, another bottleneck in deploying machine learning at scale arises after the data is in hand.
A Paradigm Shift in Development
While the greater software development world has adopted agile development and incorporated devops practices, data scientists, those tasked with developing machine learning models, are largely inexperienced when it comes to this type of workflow. Furthermore, as was discussed in version 1.0 of this overview, a key step in the workflow of data scientists is the running of hundreds, if not thousands, of experiments using different parameters and hyper-parameters in order to reach the optimal result. The intersection of data-scientists unfamiliarity of development best practices and the labor intensive nature of machine learning development has seen the creation of tens of startups aiming to augment the workflow of data scientists. Israel’s startup scene has taken center stage here with companies like Cnvrg.io and Missinglink leading the pack. The open source community has been active in this space as well, with popular tools such as Airflow and Pachyderm. Another interesting Israeli startup to keep an eye on is DAGsHub, which is built on top of the open source project DVC.
There is another, perhaps even more critical, issue we have witnessed in the past year when it comes to scaling a machine learning practice. Historically, the deployment of computational workloads and IT architecture has been aided by virtualization, the ability to run multiple, short, workloads on one computer resource. This helped firms save significant time and money, and more importantly provided them with control over and visibility into their development cycle. Machine learning workloads, and more specifically deep learning workloads, however, are fundamentally different than traditional computational workloads in that they are severely compute intensive. What this means then, is that the classic model of virtualization needs to be flipped: instead of running multiple workloads on one compute resource, in the world of deep learning we need to distribute one workload across multiple compute resources.
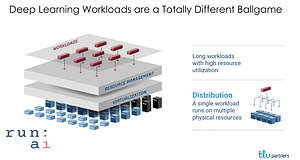
Furthermore, this distribution must take into account the specific workload, the available compute resources and costs associated with them, the size and location of the dataset/s and more. To explain it in a more dramatic, yet true, fashion, the entire stack of IT infrastructure needs to be re-imagined when it comes to machine learning. This realization is what led to our investment in RunAI.
What’s Next
One area that we have been keeping a close eye on is AI explainability (XAI). While a full description of this field is beyond the scope of this post, XAI comes to solve the “black-box” issue, namely that we don’t understand the inner workings of machine learning models. This can lead to crucial issues such as data degradation and data biases and has severe cyber security implications as well. We have yet to see much startup activity out of Israel in this field, but we hope to meet teams working on solving these problems in the coming year.
Additionally, a surprising observation we’ve made is the current preference of teams to run their machine learning practice on-premise. Due to the general cloud adoption over the past five years and the aforementioned focus all major cloud providers are placing on machine learning, it’s hard to believe that startups are investing heavily in mini GPU data centers for their offices. Looking forward we expect this trend to shift towards the cloud as the cloud providers find a way to bring down the costs associated with scaling a machine learning practice.
The World is Watching
If at the time of last year’s post Israel was not yet recognised globally as a hub for machine learning innovation, Nvidia did its best to remedy that with its near $7bn acquisition of Mellanox earlier this year. In an as pure example of infrastructure out there, Mellanox’s high performance networking technology was purchased by Nvidia in order to help power the data center of the future. With the acquisition, Nvidia joins Google, Intel, IBM, Apple, Amazon and more, as multinational corporations who have pegged Israel as a key source of AI talent. Paired with Israel’s history as a key infrastructure innovator (see USB flash drive, the Intel 8088, VoIP and more), it seems like a strong bet that Israel will continue to be a leader in developing the next generation of computing infrastructure.
We’re looking to partner with world-class teams building solutions to the pressing issues outlined above. Feel free to contact me @ Yonatan[at]tlv.partners to learn more about our view on this topic.
Thanks to Rona Segev, Shahar Tzafrir, Brian Sack, Omri Geller, Gil Elbaz, Dean Pleban and Zohar Eini for their invaluable feedback while writing this post